
The conversational AI models landscape has shifted dramatically. What was once a two-horse race between OpenAI and Google now spans four continents, with 12 frontier models competing for dominance across reasoning, speed, multilingual capability, and cost efficiency. Businesses evaluating conversational AI models in 2026 face a fundamentally different decision matrix than they did even a year ago: Chinese open-source models now rival proprietary American ones at a fraction of the cost, Europe is building sovereignty-first alternatives, and India has produced a model that outperforms ChatGPT on local language benchmarks with 667 times fewer parameters.
This post breaks down all 12 models worth evaluating, organizes them by geography and architecture, and gives you a practical framework for choosing the right one for your business. Whether you are building a customer support chatbot, a sales qualification agent, or a voice-first experience, the model you pick in 2026 will define your competitive advantage.
What Are Conversational AI Models?
Conversational AI models are large language models (LLMs) specifically designed or fine-tuned to handle multi-turn dialogue with humans. Unlike traditional chatbots that follow rigid decision trees and keyword-matching rules, conversational AI models combine three core capabilities: natural language understanding (NLU) to parse user intent, natural language generation (NLG) to produce fluent responses, and dialogue management to maintain context across an entire conversation. The result is a system that can handle ambiguity, follow up on previous statements, and adapt its responses based on conversational history.
What makes 2026 conversational AI models different from their predecessors is the integration of reasoning, tool use, and multimodal input. Models like GPT-5.2 and Claude Opus 4.6 can now chain together multi-step reasoning before responding, call external APIs mid-conversation, and process images, audio, and video alongside text. This means a single conversational AI model can now handle tasks that previously required separate NLU pipelines, retrieval systems, and orchestration layers. For businesses, this translates to simpler architectures, faster deployment, and dramatically better user experiences. You might wonder how these models compare to traditional chatbot frameworks: the answer is that modern conversational AI models have largely absorbed the functionality of those frameworks into their core capabilities, making standalone NLU engines increasingly redundant for most use cases.
Types of Conversational AI Models
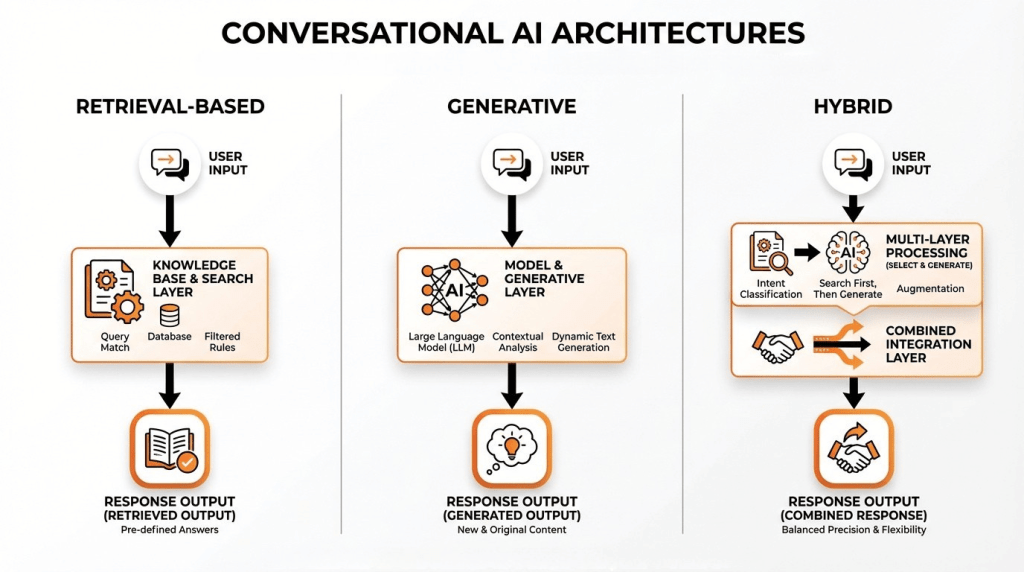
Understanding the taxonomy of conversational AI models helps you match the right architecture to your use case. The field has evolved well beyond simple categories, but four distinctions still matter in 2026.
Retrieval-based models pull responses from a pre-defined set of answers, matching user queries to the closest existing response. These are fast, predictable, and safe for regulated industries where every response must be pre-approved. They struggle with novel queries and lack the flexibility modern users expect.
Generative models produce responses from scratch using their training data and reasoning capabilities. Every frontier model covered in this post falls into this category. They excel at open-domain conversation, creative problem-solving, and handling queries the system has never seen before. The tradeoff is that they require guardrails to prevent hallucination and off-topic responses.
Hybrid models combine retrieval and generation, using a retrieval step to ground the model’s response in verified data before generating a natural-language answer. Rasa’s hybrid model stacks framework, covered later in this post, takes this further by routing queries to different models based on complexity: simple FAQs go to a small language model (SLM), complex reasoning goes to a frontier model, and a routing layer decides which path each query takes. This approach is gaining traction because it optimizes both cost and quality simultaneously.
Voice-first models represent a growing category in 2026. Mistral’s Voxtral Transcribe 2 and Sarvam AI’s voice capabilities are purpose-built for speech-to-text and text-to-speech pipelines, enabling conversational AI that works through phone calls, voice assistants, and feature phones. The distinction matters because voice models must handle disfluencies, background noise, and real-time latency constraints that text models can ignore.
A final category worth noting is task-oriented vs. open-ended models. Task-oriented models are fine-tuned for specific workflows: booking appointments, processing returns, qualifying leads. Open-ended models handle freeform conversation without a predefined goal. Most businesses need both, which is why platforms like ChatMaxima allow you to connect multiple models and route conversations based on intent.
The Geography of Conversational AI
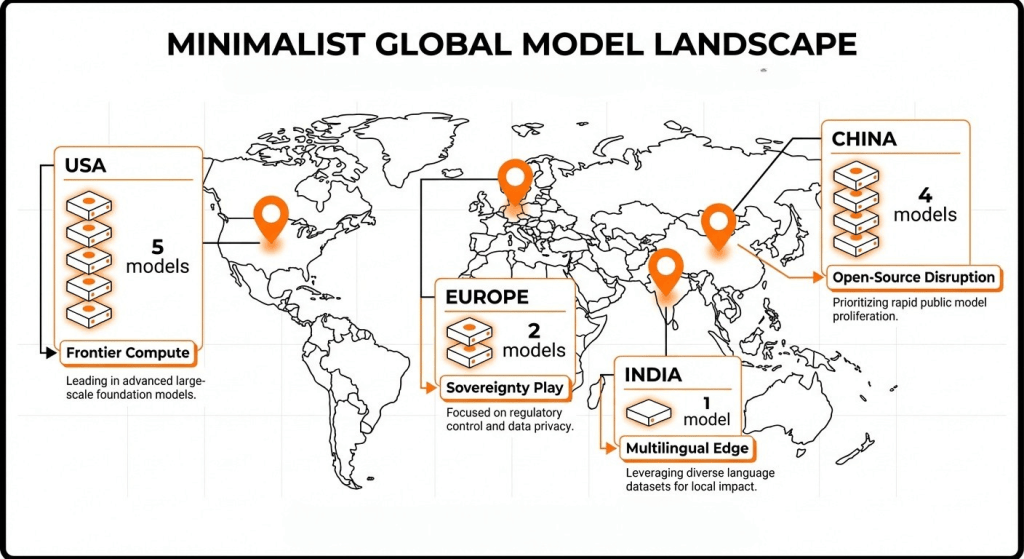
One of the most significant shifts in 2026 is that conversational AI models are no longer a Silicon Valley monopoly. The geography of where a model is built, trained, and hosted now directly impacts data sovereignty, regulatory compliance, pricing, and even model philosophy. Here is how the map looks.
United States: Five Frontier Labs
The United States remains home to the largest concentration of frontier AI labs. OpenAI (GPT-5 / GPT-5.2), Anthropic (Claude Opus 4.6 / Sonnet 4.6), Google (Gemini 3.1 Pro), Meta (Llama 4), and xAI (Grok 4.20) collectively represent the deepest investment in compute infrastructure and research talent. These labs pioneered the transformer architecture, RLHF alignment, and the scaling laws that drive modern AI. Their models tend to be proprietary-first (with the exception of Meta’s Llama), priced at premium tiers, and optimized for English-language performance. The American approach favors massive parameter counts, enormous training datasets, and tight API ecosystems that lock customers into specific platforms.
China: Four Open-Source Disruptors
China’s AI ecosystem has emerged as the most disruptive force in conversational AI pricing and open-source availability. DeepSeek V3.2 matches GPT-5 quality benchmarks at roughly 30 times lower cost. Zhipu AI’s GLM-5, released on February 12, 2026, offers 744 billion parameters completely free and open source, ranking first on the SWE-rebench coding benchmark with a 42.1% score (Z.ai blog). Moonshot AI’s Kimi K2.5 launched on January 27, 2026 with native multimodal capabilities and 100 mini AI agents, earning the second-highest open-source quality index score of 49.64. Alibaba’s Qwen3-235B rounds out the group with particularly strong multilingual performance. The Chinese approach prioritizes cost disruption and open-source release, challenging the assumption that frontier AI requires frontier pricing. For businesses watching their AI spend, these models deserve serious evaluation.
Europe: Sovereignty and Efficiency
Europe’s two entries reflect a distinctly different philosophy. Mistral AI, based in France, has positioned itself as Europe’s frontier lab with a focus on speed and efficiency. Their CEO Arthur Mensch’s quote, “Too many GPUs makes you lazy,” captures the ethos: Mistral Large 3 delivers competitive performance with significantly less compute than American rivals. Their February 4, 2026 release of Voxtral Transcribe 2 provides open-source speech-to-text, and Devstral 2 targets coding agents (Mistral blog). Rasa, based in Germany, takes an entirely different approach as a framework for hybrid model stacks rather than a single monolithic model. Their prediction that hybrid model stacks are the future resonates with enterprises that need EU AI Act compliance, data residency guarantees, and the ability to mix and match models from different providers.
India: Sovereign AI for 1.4 Billion People
Sarvam AI’s Sarvam-105B represents something entirely new: a model purpose-built for a specific population’s linguistic needs under government backing through the IndiaAI Mission. Supporting 22 Indian languages with edge and offline deployment capabilities, Sarvam-105B works on feature phones, a critical requirement for reaching India’s population beyond smartphone users. The model beat ChatGPT and Gemini on India-specific benchmarks despite being 667 times smaller, proving that domain-specific optimization can outperform brute-force scaling. For any business serving Indian customers or operating in Indian languages, this model is not optional, it is necessary.
The geographic distribution of AI development matters for three practical reasons. First, data sovereignty: where your model is hosted and who controls the training data affects GDPR, India’s DPDP Act, and China’s data localization laws. Second, regulatory compliance: the EU AI Act imposes specific requirements on AI systems deployed in Europe, making European-built models a natural compliance advantage. Third, cost: Chinese open-source models have fundamentally disrupted pricing, and businesses that ignore them are leaving money on the table.
Top Conversational AI Models in 2026
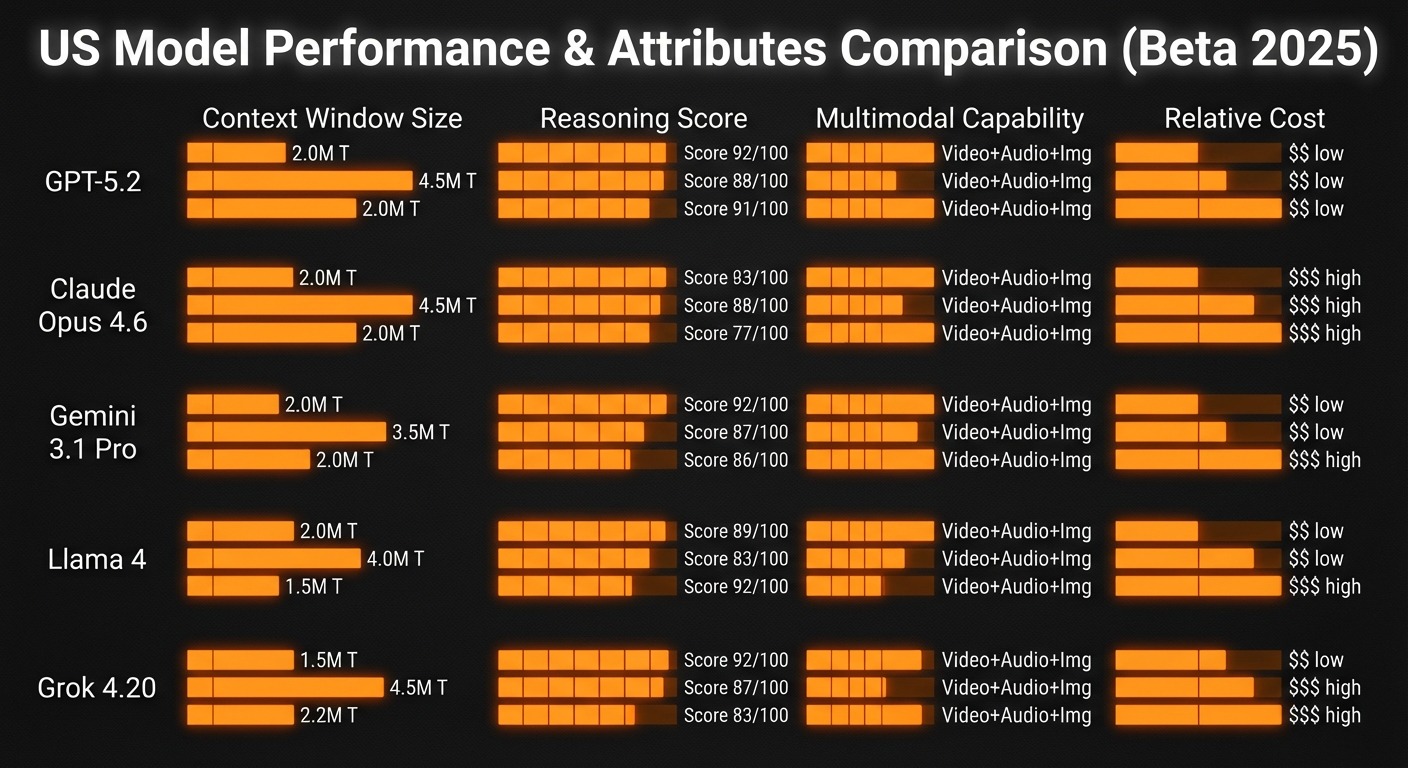
GPT-5 / GPT-5.2 (OpenAI, USA)
OpenAI’s flagship remains the default choice for many enterprises. GPT-5.2 introduced deep research mode, which chains together extended reasoning steps before responding, and an improved voice mode that supports real-time conversational speech. The model excels at complex reasoning tasks, creative writing, and multi-step instruction following. Its LMArena Elo score consistently places it among the top three models globally. The primary drawbacks are cost (substantially higher per token than Chinese alternatives) and the proprietary nature of the platform. ChatMaxima integrates directly with OpenAI models, enabling businesses to deploy GPT-5.2 across WhatsApp, Instagram, web chat, and other channels without building custom infrastructure. For a detailed breakdown of accessing the latest OpenAI models and their performance benchmarks, see this guide on GPT model access and pricing.
Claude Opus 4.6 / Sonnet 4.6 (Anthropic, USA)
Released in February 2026, Claude Opus 4.6 represents Anthropic’s strongest entry in the reasoning and coding categories. The model handles long-context analysis exceptionally well, processing documents of 200,000+ tokens with high fidelity. Sonnet 4.6 offers a smaller, faster variant optimized for production workloads where latency matters more than maximum capability. Claude’s constitutional AI approach to safety makes it particularly attractive for regulated industries like healthcare, finance, and legal services. The model’s coding performance rivals specialized coding assistants, making it a strong choice for developer tools and technical support chatbots.
Gemini 3.1 Pro (Google, USA)
Google’s Gemini 3.1 Pro holds the largest context window of any frontier model in February 2026, enabling it to process entire codebases, lengthy legal documents, or extended conversation histories without losing context. Its native multimodal capabilities allow it to process text, images, video, and audio in a single prompt, making it the strongest choice for applications that need to reason across different media types simultaneously. The deep integration with Google Cloud services and Vertex AI gives enterprises a streamlined deployment path, though this also creates platform lock-in that some organizations prefer to avoid.
Llama 4 (Meta, USA)
Meta’s Llama 4 continues the tradition of high-quality open-source models that organizations can self-host and fine-tune without licensing restrictions. For businesses with strong engineering teams and specific data privacy requirements, Llama 4 provides the control that proprietary APIs cannot. The model performs well across general conversational tasks and benefits from an enormous open-source community that produces fine-tunes, quantizations, and deployment tools. The tradeoff is that self-hosting requires significant infrastructure investment, and the model’s raw performance trails the top proprietary offerings on most benchmarks.
Grok 4.20 (xAI, USA)
xAI’s Grok 4.20, released in February 2026, has emerged as a surprisingly strong new entrant. Built with access to real-time data from X (formerly Twitter) and other sources, Grok brings a unique advantage in tasks requiring current information. Its conversational style is distinctly less filtered than competitors, which appeals to certain use cases but requires careful evaluation for customer-facing deployments. Early benchmark results suggest competitive performance with GPT-5 on reasoning tasks, though the model’s ecosystem and enterprise tooling remain less mature than established players.
DeepSeek V3.2 (DeepSeek, China)
DeepSeek V3.2 is the model that made the AI industry reconsider its assumptions about the relationship between cost and quality. Matching GPT-5 on multiple public benchmarks while costing roughly 30 times less to run, DeepSeek demonstrated that efficient architecture design can substitute for raw compute spending. The model is fully open source, allowing self-hosting and fine-tuning. With V4 imminent, DeepSeek’s trajectory suggests that the cost gap between Chinese and American models will continue to widen. Businesses that route high-volume, lower-complexity queries through DeepSeek while reserving premium models for complex tasks can dramatically reduce their AI spend. Platforms like OpenRouter make this multi-model routing straightforward.
GLM-5 (Zhipu AI / Z.ai, China)
GLM-5 launched on February 12, 2026 with 744 billion parameters, making it one of the largest open-source models ever released, and it is completely free to use. Its standout achievement is ranking first on SWE-rebench with a 42.1% score, establishing it as the leading model for agentic software engineering tasks. GLM-5’s design philosophy centers on autonomous coding agents that can plan, execute, and debug multi-file changes across large codebases. For businesses building AI-powered development tools or internal automation agents, GLM-5’s combination of scale, capability, and zero cost makes it an exceptional option.
Kimi K2.5 (Moonshot AI, China)
Kimi K2.5 launched on January 27, 2026 with native multimodal capabilities spanning text, image, and video processing. Its architecture includes 100 mini AI agents that can be deployed for specialized sub-tasks, a design choice that pushes toward the agentic AI paradigm where models coordinate multiple specialized workers rather than handling everything monolithically. Kimi K2.5 earned the second-highest open-source quality index score of 49.64 and is available on AWS Bedrock, making it accessible to enterprises already invested in the AWS ecosystem. The combination of multimodal capability, agentic architecture, and cloud marketplace availability makes Kimi K2.5 one of the most versatile Chinese models for production deployment.
Qwen3-235B (Alibaba, China)
Alibaba’s Qwen3-235B delivers particularly strong multilingual performance, reflecting Alibaba’s global e-commerce footprint across dozens of languages and markets. The model is open source and performs competitively on reasoning and coding benchmarks. For businesses operating across multiple geographies and languages, Qwen3’s training data diversity gives it an edge over models primarily optimized for English. Its relatively moderate parameter count (compared to GLM-5’s 744B) also makes it more practical to self-host for organizations with limited GPU infrastructure.
Mistral Large 3 / Voxtral Transcribe 2 (Mistral AI, France)
Mistral AI has earned the “speed king” reputation by delivering competitive model quality with dramatically lower latency than American rivals. Mistral Large 3 processes requests faster than most frontier models, making it the preferred choice for real-time conversational applications where response speed directly impacts user experience. Voxtral Transcribe 2, released on February 4, 2026, provides open-source speech-to-text capability, and Devstral 2 targets coding agents. Mistral’s Vibe 2.0 platform ties these models together into a cohesive development environment. For inference speed optimization, Groq’s hardware acceleration pairs exceptionally well with Mistral models, delivering sub-second response times for production chatbots.
Rasa (Germany)
Rasa takes a fundamentally different approach from every other entry on this list. Rather than offering a single model, Rasa provides a framework for building hybrid model stacks that combine small language models (SLMs) for simple tasks, frontier models for complex reasoning, and an intelligent routing layer that decides which model handles each query. This architecture directly addresses the cost and latency concerns that plague single-model deployments: simple FAQ responses run on fast, cheap SLMs while complex customer issues escalate to GPT-5 or Claude. Rasa’s prediction that hybrid model stacks are the future aligns with what we see enterprises building in practice, and tools like OpenRouter enable similar multi-model routing for businesses that want this approach without building from scratch.
Sarvam-105B (Sarvam AI, India)
Sarvam-105B is the first conversational AI model to comprehensively address the Indian market’s unique requirements. Built under the IndiaAI Mission with government backing, it supports 22 Indian languages with native fluency rather than translation-layer approximation. The model is optimized for edge and offline deployment, running on feature phones, a requirement that no American or Chinese model has prioritized. On India-specific benchmarks covering cultural context, regional language nuance, and local knowledge, Sarvam-105B beat both ChatGPT and Gemini despite being 667 times smaller. This is sovereign AI done right: purpose-built for a specific population’s needs rather than adapted from a general-purpose model after the fact.
How to Choose the Right Model for Your Business
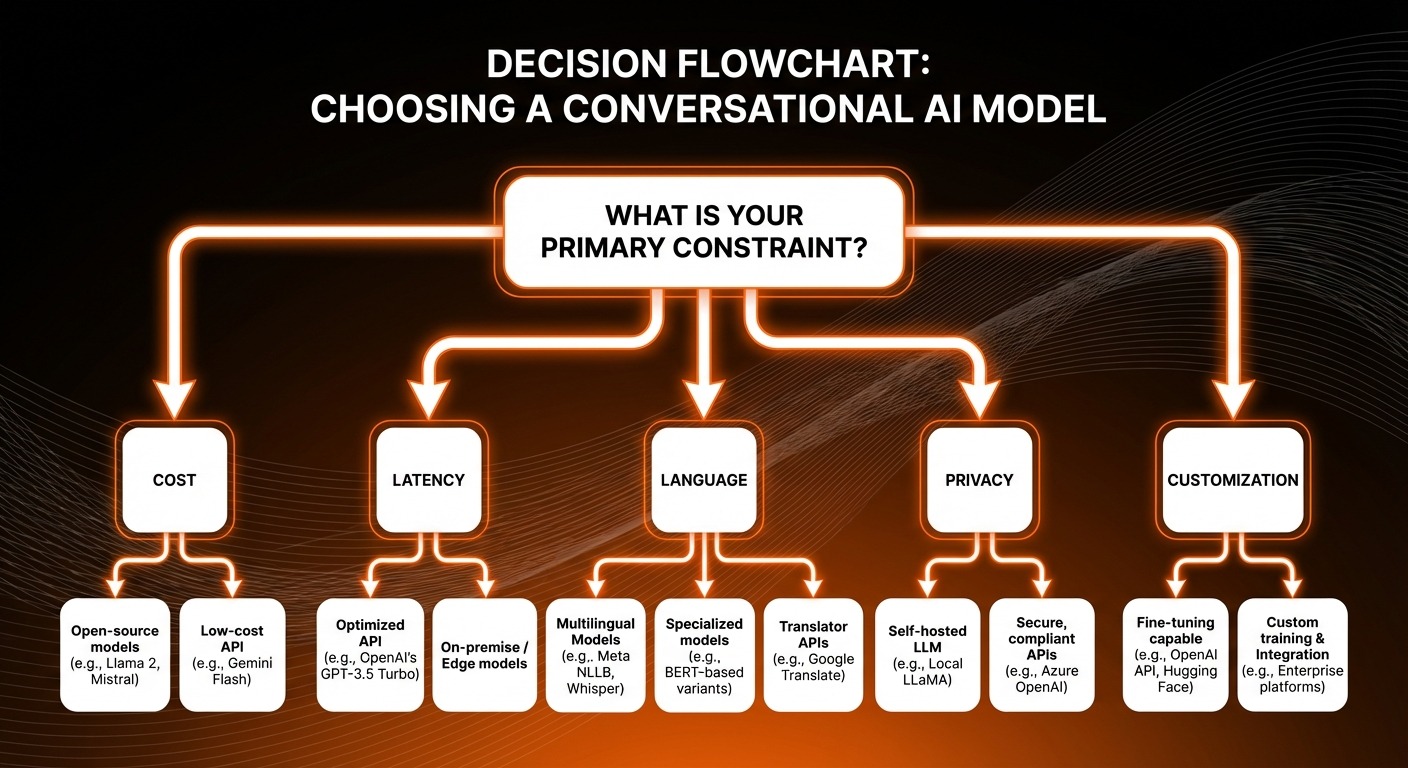
Selecting from 12 competitive conversational AI models requires a structured decision framework rather than defaulting to brand recognition. Five factors should drive your evaluation.
Cost per conversation varies by orders of magnitude across these models. GPT-5.2 and Claude Opus 4.6 sit at the premium tier, while DeepSeek V3.2 and GLM-5 offer comparable quality at dramatically lower prices (or free). Calculate your expected monthly conversation volume, multiply by per-token costs, and compare. For most businesses, the optimal strategy is not choosing one model but routing different conversation types to different models based on complexity. Check ChatMaxima’s pricing to see how multi-model deployment can work within a unified platform.
Latency requirements depend on your use case. Voice-first applications and live chat demand sub-second responses, favoring Mistral Large 3 and models served through Groq’s inference hardware. Async support tickets can tolerate longer processing times, opening the door to more powerful but slower models.
Language support is a dealbreaker for global businesses. If you serve Indian customers, Sarvam-105B is non-negotiable. If you operate across Southeast Asia, Qwen3-235B’s multilingual training gives it an edge. English-only businesses have more flexibility but should still evaluate multilingual capability as a future-proofing measure.
Data privacy and deployment model determine whether you can use cloud APIs or need self-hosted models. Open-source options (Llama 4, DeepSeek V3.2, GLM-5, Qwen3-235B) allow on-premises deployment that keeps customer data entirely within your infrastructure. Proprietary APIs (GPT-5.2, Claude, Gemini) are simpler to deploy but route data through third-party servers. For enterprise deployments requiring compliance with specific data residency laws, Azure AI provides managed hosting with contractual compliance guarantees.
Open source vs. proprietary is no longer a quality tradeoff. Chinese open-source models have closed the quality gap, making the decision about control, customization, and vendor lock-in rather than capability. Organizations with engineering teams that can manage model deployment benefit from open source. Those that prefer managed services and guaranteed SLAs should lean toward proprietary offerings.
Conversational AI Models for Customer Engagement
The practical impact of these models shows up most clearly in customer engagement deployments. Businesses in 2026 are using conversational AI models across three primary workflows: customer support resolution, sales qualification and conversion, and customer onboarding automation.
For customer support, the winning architecture combines a fast, affordable model for first-contact resolution of common queries (DeepSeek V3.2 or an SLM through Rasa’s hybrid stack) with a frontier model (Claude Opus 4.6 or GPT-5.2) for complex escalations requiring nuanced reasoning. This tiered approach can reduce support costs by 40-60% while maintaining resolution quality for difficult cases. The key is intelligent routing: using intent classification to send each query to the appropriate model tier.
Sales qualification benefits from models with strong reasoning and persuasion capabilities. GPT-5.2’s deep research mode and Claude’s long-context analysis excel at understanding prospect needs, matching them to product capabilities, and guiding conversations toward qualified handoffs to human sales teams. Kimi K2.5’s 100 mini agents architecture enables parallel research during sales conversations, pulling in product specs, competitor comparisons, and pricing details while the primary conversation continues.
Omnichannel deployment is where the platform layer matters as much as the model. Customers expect consistent AI experiences across WhatsApp, Instagram DM, web chat, SMS, email, and voice. ChatMaxima’s omnichannel platform connects these conversational AI models to every major messaging channel through a single integration layer, so you configure your AI agent once and deploy it everywhere. This eliminates the engineering overhead of maintaining separate integrations for each channel and each model.
Trends Shaping Conversational AI Models in 2026
Seven trends are reshaping how businesses think about and deploy conversational AI models this year.
Agentic AI is the biggest architectural shift. Models are moving from reactive (respond to a query) to proactive (plan and execute multi-step tasks autonomously). GLM-5’s SWE-rebench dominance and Kimi K2.5’s 100 mini agents both reflect this trend. In customer engagement, agentic AI means chatbots that do not just answer questions but actually resolve issues: processing refunds, updating account settings, scheduling appointments, and following up automatically. According to No Jitter’s 2026 analysis, agentic capabilities will define the next generation of enterprise AI deployments.
Voice-first and multimodal interactions are accelerating. Mistral’s Voxtral Transcribe 2, Sarvam’s voice capabilities, and OpenAI’s improved voice mode all signal that text-only conversational AI is becoming insufficient. Businesses serving populations with lower literacy rates, hands-busy use cases (driving, cooking, manufacturing), or phone-centric markets need voice-native AI. Multimodal models like Gemini 3.1 Pro and Kimi K2.5 add visual understanding, enabling conversations where customers can share photos of broken products, receipts, or error screens and receive contextual help.
The sovereign AI movement is gaining political and economic momentum. India’s government-backed Sarvam, Europe’s Mistral, and various national AI strategies reflect a growing consensus that depending entirely on American or Chinese AI infrastructure creates strategic vulnerability. Expect more country-specific and region-specific models optimized for local languages, legal frameworks, and cultural contexts.
Edge deployment is moving from aspiration to production. Sarvam-105B’s ability to run on feature phones demonstrates that conversational AI does not require cloud connectivity. For industries like agriculture, mining, field service, and rural healthcare, edge-deployed models that work offline and on low-bandwidth connections unlock markets that cloud-only AI cannot reach.
Hybrid model stacks, as championed by Rasa, represent the maturation of enterprise AI architecture. Rather than betting everything on a single model, sophisticated deployments route different query types to different models, balancing cost, latency, and quality dynamically. This approach also provides resilience: if one model provider experiences an outage or price increase, traffic can shift to alternatives without disrupting the user experience.

Cost compression continues to reshape the market. DeepSeek’s 30x cost advantage over GPT-5 is not an anomaly but a trend. As Chinese labs release more efficient architectures and open-source alternatives proliferate, the cost of running conversational AI will continue to drop. Businesses that locked into expensive per-token pricing in 2024-2025 should re-evaluate their contracts.
Model routing and orchestration is emerging as a distinct product category. The question is no longer “which model should I use?” but “how do I use the right model for each conversation turn?” Tools like OpenRouter and platforms like ChatMaxima that support multiple model backends are becoming essential infrastructure for any serious conversational AI deployment.
What Comes Next
The conversational AI models available in 2026 represent a step change in capability, accessibility, and geographic diversity. The era of choosing between “GPT or nothing” is over. Businesses now have genuine options across the cost-quality spectrum, from free open-source models that rival frontier proprietary ones to specialized models built for specific languages and deployment environments.
The practical advice is straightforward: do not commit to a single model. Build your conversational AI stack on a platform that supports multi-model routing, so you can swap, combine, and optimize as the landscape evolves. Start with your highest-volume, lowest-complexity conversations and route them through cost-effective models like DeepSeek V3.2 or Qwen3-235B. Reserve premium models for complex reasoning tasks where quality directly impacts revenue. And evaluate every model on this list against your specific use case rather than relying on generic benchmark rankings.
The companies that win with conversational AI in 2026 will not be the ones using the “best” model. They will be the ones using the right model for each conversation, deployed across every channel their customers use, at a cost that scales with their business. Start building your multi-model conversational AI stack today.

