
A frontier model can go from launch to unreachable in the same week. A pricing change, a region lock, a new export rule, or a single regulatory directive can pull a capability that millions of businesses depend on, and there is nothing a customer can do about it from the outside. This is the uncomfortable truth that model independence forces every serious AI team to confront.
When a model is reachable through a single shared endpoint that serves customers in many countries at once, there is no clean way to filter who gets access by nationality. You cannot filter a shared pipe by passport. So when a regulator says one group of users cannot use it, the only mechanism that actually complies is to shut the endpoint off for everyone. The capability stops flowing worldwide, overnight, for reasons that have nothing to do with the quality of the model.
If you are building AI infrastructure, that scenario should change how you architect. The most important decision is not which model is best today. It is whether your architecture can survive losing that model tomorrow. This post explains why the model is a dependency rather than a foundation, what the real failure modes look like, and how to build a stack that no single directive can switch off.
The Strait of Hormuz lesson for AI
The Strait of Hormuz is a narrow waterway that roughly a fifth of the world’s oil passes through. It is not the source of the oil and it is not the destination. It is a chokepoint. And because so much flow is forced through one narrow place, whoever controls that point controls far more than their share of the map.
AI is developing its own chokepoints. The compute, the frontier weights, the inference endpoints, and the legal right to serve them across borders are concentrating into a small number of narrow straits. When everything routes through one of them, a decision made in a room you will never enter can choke the flow for your entire business.
The lesson is not “avoid the strait.” Oil tankers still use Hormuz. The lesson is that anyone whose survival depends on a single chokepoint has handed control of their future to whoever holds that point. The infrastructure that survives a chokepoint event is the infrastructure that was never fully dependent on it in the first place.
The model is not the foundation, it is a dependency
Here is what most infrastructure teams get wrong. They treat the model as the foundation, the bedrock everything else is poured on top of. So they optimize the whole stack around the quirks, the prompt format, the token limits, and the function-calling style of one provider.
That feels efficient. It is actually fragile.
The model is not the foundation. It is a dependency. And dependencies fail in ways you do not control:
- Pricing shifts. A provider can change per-token pricing, and a workload that was profitable becomes a loss overnight.
- Region locks. A model becomes unavailable in a country your customers operate in, with no appeal process.
- Export law. New rules restrict who is allowed to access a capability based on where they sit.
- Retention and data policy. A change to how prompts are logged or trained on can break a compliance posture you promised your own customers.
- A single directive. A regulatory letter can force a provider to shut an endpoint off for everyone at once.
None of these are about whether the model is good. They are about the fact that the model sits outside your control boundary. Treating something outside your control as the foundation of your product is the architectural mistake. You can read more about how the model landscape itself keeps shifting in our breakdown of conversational AI models in 2026.
Why a shared endpoint cannot filter by passport
It helps to understand the technical reason a cutoff has to be total rather than targeted.
A frontier model is usually served from a shared inference endpoint. The same cluster, the same weights, and the same API surface serve a customer in San Francisco, a team in Singapore, and a startup in Bahrain. Requests arrive, get batched together for efficiency, and are answered from the same pool of accelerators.
That shared design is exactly what makes the model affordable and fast. It is also what makes selective enforcement nearly impossible. If a directive says one nationality cannot use the capability, the provider cannot reliably separate those requests inside a shared pipe without rebuilding the serving layer. Identity at the API boundary is an API key, not a verified passport, and keys move across borders freely.
So the provider is left with one switch that actually works: turn the endpoint off. For everyone. That is why these events are so blunt. The compliance mechanism available is a valve, not a filter. When the only available control is a valve, the blast radius is everyone downstream.
What model independence actually looks like
Model independence is not a feature you bolt on after launch. It is the foundation you pour first, before the model, before the prompts, before the product. Concretely, it is four layers.
A routing layer
Every model call in your system goes through one internal routing layer, never directly to a provider SDK scattered across your codebase. The routing layer decides which provider and which model handles a given request based on configuration, not hardcoded calls. Swapping a provider becomes a config change, not a refactor.
A provider abstraction
Each provider has its own prompt format, its own function-calling schema, its own streaming behavior, and its own error codes. A clean abstraction normalizes all of that into one internal contract. Your application code speaks one language. Adapters translate it into whatever each provider expects. When a new provider appears, you write one adapter, not a thousand edits.
Fallback and failover logic
When the primary model returns an error, times out, or goes dark entirely, the routing layer should fall back to a secondary provider automatically. The conversation in front of your customer should never hiccup. This is the difference between a provider outage being a minor internal event and being a public failure your customers feel.
Portable context and state
The conversation history, the retrieved knowledge, the tools, and the memory must live in your system, not inside one provider’s session abstraction. If switching models means re-uploading context or rebuilding state, you are not actually independent. The model should be able to change underneath a live conversation while the context stays exactly where it is.
Build these four layers and the model becomes a setting. Skip them and the model becomes a single point of failure you cannot see until it fails. This is the same architectural argument we make in detail when comparing a platform approach against building your own chatbot on a raw OpenAI API, where the hidden cost is almost always the lock-in, not the first build.
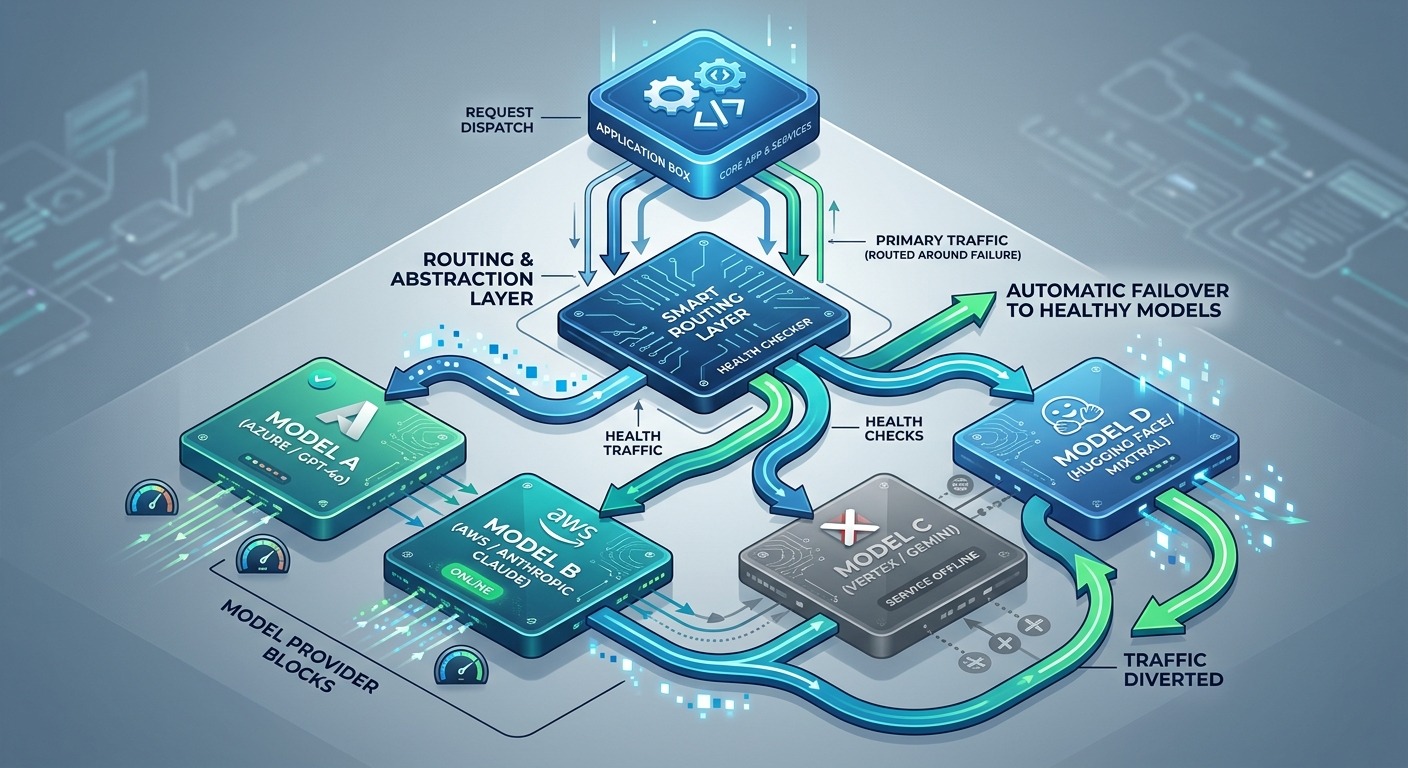
How model independence plays out when a cutoff hits
The value of this architecture is invisible right up until the moment it is the only thing keeping you online.
Picture the cutoff. A frontier model that a large set of businesses were running on becomes unreachable across an entire set of regions, with effectively no notice. Teams that wired their product directly to that model are now staring at a re-architecture in the middle of an incident. Re-integration. New prompt formats. New function-calling schemas. New testing. Days of work while their own customers sit in the dark.
Now picture the team that poured model independence first. The primary model goes dark. The routing layer detects the failure and shifts traffic to another provider. The abstraction layer already speaks that provider’s dialect. The context never moved. The switch takes minutes, and most of those minutes are someone confirming the change rather than building it.
No re-architecture. No re-integration. No downtime. The conversation with the end customer never even notices. That is the entire payoff: the people you serve should never lose their platform because of a decision made in a room they will never enter.
At ChatMaxima we made this call early, when it looked paranoid. No model lock-in, ever. Customers do not run on any single model. They run on ChatMaxima, and the model underneath is a setting they control, not a foundation they are trapped on. That principle is also why our vertical AI agents can outperform a generic single-model assistant, because the routing layer can send the right task to the right model instead of forcing everything through one.
The objection: is model independence just more work?
The honest pushback on all of this is that an abstraction layer is more engineering than calling a provider SDK directly. That is true on day one. It is false over any horizon that matters.
Building straight onto one provider is faster to ship and slower to change forever after. Every prompt you tune to one model’s quirks, every function-calling schema you hardcode, and every place you parse one provider’s error format is a small loan against your future flexibility. The interest on that loan comes due all at once, on the worst possible day, when you need to move and discover the cost is a rewrite.
Model independence front-loads a bounded, predictable cost: design the routing layer and the abstraction once. After that, adding a provider is one adapter and switching is a config change. The lock-in path back-loads an unbounded, unpredictable cost that lands during an incident. One of those is an engineering decision. The other is a gamble dressed up as a shortcut.
There is also a quieter benefit teams underestimate. When the model is a setting, you can route by task. Send a cheap, fast model the simple classification work and reserve the expensive frontier model for the hard reasoning. You can run an evaluation across providers without rebuilding anything. You can adopt a better model the week it ships instead of the quarter you finish migrating. Independence is not only insurance against a cutoff. It is leverage you use every single day.
Data residency is the next chokepoint
Export controls get the headlines, but data residency is the slower, broader version of the same squeeze. More countries every year require that customer data, and increasingly the inference that runs on it, stay within their borders. A model served only from one region is a compliance problem the moment your customer is in a jurisdiction that mandate covers.
Model independence is what makes residency tractable. If your routing layer can send a request to a provider or a deployment inside the right region, you can honor a residency requirement without telling your customer to wait for a roadmap. If you are locked to one global endpoint, your only answer to a residency demand is “we cannot,” and that answer loses deals and breaks contracts. The same abstraction that protects you from a cutoff is the abstraction that lets you say yes to a regulated enterprise.
A checklist for model-independent AI infrastructure
If you want to test how independent your own stack really is, walk through these questions honestly.
Could you switch your primary model today with a config change? If switching requires editing application code in more than one place, your routing layer is not centralized enough.
Does your application code import any provider SDK directly? Direct imports outside the abstraction layer are lock-in waiting to happen. Every call should go through your own internal interface.
What happens to a live conversation if the primary provider returns a 500 right now? If the answer is “the user sees an error,” you have no failover. If the answer is “it retries the same provider forever,” you have a different failure.
Where does conversation context physically live? If it lives inside one provider’s session object, you cannot move it without rebuilding it. It should live in your own store.
If a provider doubled its price tonight, how long until you could move volume elsewhere? The honest answer is a direct measure of your independence. Minutes is healthy. Weeks means you are exposed.
Have you ever actually run on your secondary provider in production? A fallback you have never exercised is a fallback you do not have. Route real traffic through it periodically so you know it works before you need it.
If several of those answers make you uncomfortable, that is useful. It is far better to find the gaps during a calm review than during a cutoff. Connecting and switching between providers is exactly the kind of work a mature platform should make routine, which is why this lives at the integrations layer rather than buried in application code.
The next decade of AI is shaped by geography, not just capability
For the last few years the AI conversation has been almost entirely about capability. Which model is smartest. Which benchmark moved. Which lab shipped first. That framing is about to feel incomplete.
The next decade will be shaped at least as much by geography and governance as by raw capability. Sovereignty. Data residency. Export controls. The question of who is allowed to compute what, and where. Governments are already treating advanced AI the way they treat strategic resources, and export control regimes like those administered by the US Bureau of Industry and Security (bis.doc.gov) are extending into compute and capability, not just hardware. None of that is hypothetical, and none of it is going away.
In that environment, the teams that survive will not be the ones who bet everything on the single best model. They will be the ones who built so that no single provider, and no single directive, could ever hold them hostage. Capability is a moving target. Independence is a durable position.
This is also a trust question with your own customers. A business that runs its support, its sales conversations, and its customer data on top of one provider is implicitly asking its customers to trust that provider’s roadmap and that provider’s regulators. A business built on model independence is making a different promise: your channels, your data, and your model choice belong to you.
Own your channels, own your data, own your model choice
The summary is short. Own your channels. Own your data. Own your model choice. Build on infrastructure that no single directive can switch off.
Model independence is not paranoia and it is not a premium add-on. It is the foundation you pour first so that everything above it can survive the things you do not control. The routing layer, the provider abstraction, the failover logic, and the portable context are not optional polish. They are the load-bearing structure of any AI product that intends to still be running after the next chokepoint event.
If you are building AI infrastructure, ask yourself the one question that matters: how would your stack hold up if your primary model vanished tonight? If the honest answer is “not well,” that is the most important thing on your roadmap, and it should move to the top.
ChatMaxima was built around that answer from day one: conversational AI infrastructure that belongs to the business using it, not to the lab that trains the model or the government that regulates it. If you want a platform where the model is a setting rather than a single point of failure, see how it works and what it costs on our pricing page, and build on something the next directive cannot switch off.

