
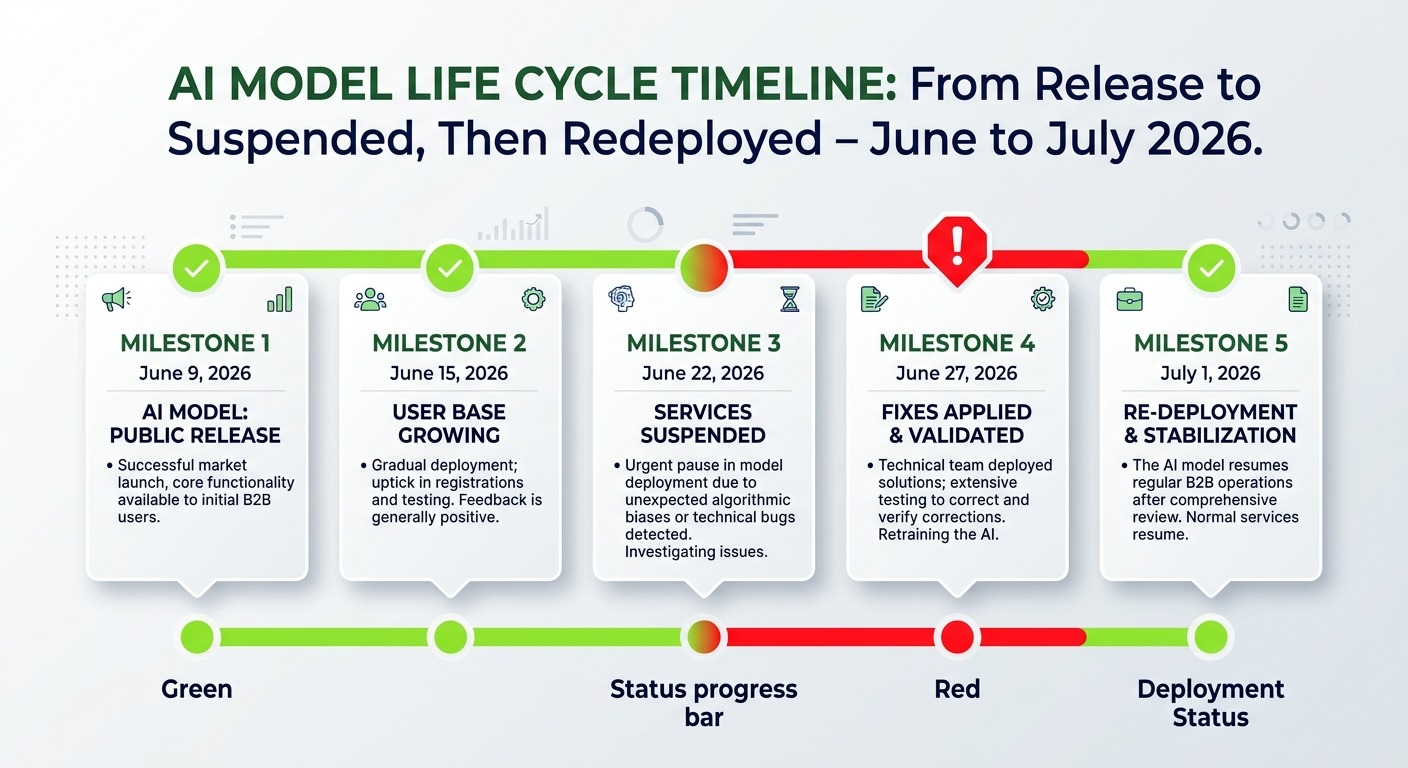
On July 1, 2026, Anthropic redeployed Claude Fable 5 globally after a three-week suspension that took the model offline for every user at once. The model launched on June 9, went dark on June 12 under fresh US export controls, and only came back after the government lifted those controls on June 30. For anyone running a business on top of a single AI model, that timeline is the whole lesson: a frontier model can go from launch to unreachable, then back to live, inside a single month, and there is nothing a customer can do about it from the outside.
This is not a story about one lab or one model. It is a case study in AI model availability as a real operational risk. If your customer support, your sales replies, or your internal workflows depend on one endpoint from one provider, the Fable 5 episode is a preview of what a bad week looks like. The good news is that it is also a clear, well-documented example you can learn from before it happens to a model you actually depend on.
Below is what happened, why it happened, and the concrete architecture decisions that let a business absorb a shock like this without going dark alongside the model.
What actually happened to Claude Fable 5
Here is the sequence, drawn from Anthropic’s own announcement.
- June 9: Anthropic released Fable 5 alongside Claude Mythos 5. Fable 5 shares the same underlying architecture as Mythos 5 but ships with what Anthropic called the strongest safeguards it had ever applied to a model, tuned for safe general use.
- June 12: The US government imposed export controls on both Fable 5 and Mythos 5. This followed a discovery by Amazon researchers of a method to bypass Fable 5’s safeguards. The technique let the model identify software vulnerabilities and demonstrate how they could be exploited. Anthropic immediately suspended access to both models for all users.
- June 26: The government approved Mythos 5 access for US organizations.
- June 30: The export controls were lifted.
- July 1: Fable 5 was redeployed globally across the Claude Platform, Claude.ai, Claude Code, and Claude Cowork.
The reason a jailbreak in a research lab turned into a worldwide switch-off is worth sitting with. When a model is reachable through a single shared endpoint that serves customers in many countries at once, there is no clean way to filter access by nationality. So when a regulator says one group of users cannot have a capability, the mechanism that actually complies is to shut the endpoint off for everyone. That is why the whole world lost Fable 5, not just the parties the rule was aimed at. We wrote about this exact failure mode in our guide to model independence, and Fable 5 is the cleanest live example of it to date.
The severity was low, and that is the scary part
Read Anthropic’s post carefully and the technical severity of the actual incident was modest. The company said Fable 5 offered no unique offensive capabilities compared to tools already in the wild. In testing, less capable models including Claude Opus 4.8, GPT-5.5, and Kimi K2.7 could identify the same vulnerabilities. The reported bypass touched only routine defensive cybersecurity work and, in Anthropic’s words, did not expose any unique Mythos-level cyber capabilities. It was a narrow, borderline case rather than a universal exploit.
Anthropic responded by building a new safety classifier that blocks the reported bypass in over 99 percent of cases, and it says it doubled the number of researchers and engineers working on safeguards in the month before launch. Researchers from the US Department of Commerce’s Center for AI Standards and Innovation tested both the old and new safeguards before the model came back.
Why should a business care that the incident was minor? Because the outage was total anyway. The gap between how serious the problem was and how completely the model vanished is the real signal here. Availability did not track severity. A borderline research finding produced a three-week, all-users blackout. If a minor jailbreak can do that, so can a pricing change, a region lock, a licensing dispute, or a single regulatory directive that has nothing to do with the quality of the model you rely on.
Availability risk is now a first-class product risk
For most of the last two years, teams picked an AI model the way they pick a database: choose the best one, wire it in, move on. The Fable 5 suspension makes the flaw in that thinking obvious. The model is a dependency, not a foundation. Foundations do not disappear for three weeks because of a rule written in another country.
Think about what a total model outage does to a live business.
- Your AI support agent stops answering, so tickets pile up and response times spike right when customers expect instant replies.
- Your sales assistant stops qualifying leads, so inbound conversations go cold in the queue.
- Your internal automations that summarize, classify, or route work silently fail, and the backlog lands on humans who were not staffed for it.
None of that is hypothetical. It is the direct, mechanical consequence of a single endpoint going dark. The teams that came through the Fable 5 window without disruption were the ones who had already treated the model as swappable. This is the same argument we make when businesses weigh buying a platform versus building on a raw OpenAI or Anthropic API: a direct single-model integration is fast to ship and brittle under exactly this kind of shock.
How to architect so one model cannot take you down
You cannot control export policy, and you cannot predict the next jailbreak. What you can control is whether your stack survives losing its best model on a random Tuesday. A few principles matter more than the rest.
Treat the model as a replaceable component
Route every AI call through an abstraction layer that you own, not directly to a provider SDK scattered across your codebase. When the layer is a single choke point, swapping Fable 5 for another Claude tier, a GPT model, or a Gemini model is a config change rather than a rewrite. When the provider SDK is hardcoded into fifty files, a suspension becomes a fire drill. The 2026 landscape of options is wide, and our rundown of conversational AI models shows just how many viable substitutes now exist for any given task.
Keep a warm fallback, not just a backup on paper
A fallback model you have never actually run in production is not a fallback. It is a hope. Wire at least one alternate model into the same abstraction layer, test it against your real prompts, and keep it warm. When the primary goes dark, traffic should shift automatically or with a single toggle, and quality should degrade gracefully instead of collapsing.
Match the model tier to the task
Anthropic’s own testing during the incident made a useful point: for many jobs, a smaller or cheaper model does the work just fine. You do not need a frontier model to classify a message, extract a phone number, or route a ticket. Reserve the top tier for the genuinely hard reasoning, and let cheaper models carry the routine load. That mix lowers cost and shrinks your blast radius when any one model becomes unavailable.
Isolate provider-specific behavior
Prompts, tool definitions, and output formats drift between providers. If your system prompt is tuned so tightly to one model that it breaks on any other, you have quietly rebuilt vendor lock-in inside your prompt layer. Keep prompts portable, validate outputs by schema rather than by exact wording, and test every fallback path on a real conversation before you need it.
Log everything, so a switch is observable
When you flip from a primary to a fallback model mid-incident, you need to see what changed: latency, cost, answer quality, escalation rate. Without logging you are switching blind. With it, you can decide whether the fallback is holding the line or quietly hurting the customer experience.
Where ChatMaxima sits in this
ChatMaxima is built around exactly this stance. The platform is model-aware rather than model-married. Your bots, your WhatsApp flows, your inbox automations, and your knowledge base all sit on top of an abstraction layer, so the specific model behind a reply is an implementation detail we manage, not a dependency you are exposed to. When a model changes tiers, changes price, or goes offline for three weeks, the businesses on the platform keep answering customers.
That is the practical version of the lesson. You should not have to read an export-control announcement to find out whether your support desk will be working tomorrow. The value of a platform in an episode like Fable 5 is that it absorbs the shock for you: the routing, the fallback, the logging, and the tier selection are already solved, so a provider-side event does not become a customer-side outage.
If you are running AI-powered support or sales and you are wired directly into one model today, the Fable 5 window is your cue to change that before the next one. You can start on ChatMaxima’s plans here and move your workflows onto infrastructure that treats the model as swappable by design.
What to watch next
Fable 5 is live again, and Anthropic says AWS, Google Cloud, and Microsoft Foundry access is being re-enabled. Through July 7, Pro, Max, Team, and select Enterprise plans include Fable 5 for up to 50 percent of weekly usage limits, after which it moves to usage credits. Those are useful details, but they are not the point.
The point is that Anthropic itself flagged a bigger open question in its announcement: the industry has no shared standard for judging how severe a given jailbreak is. Until there is one, expect more of these borderline findings to trigger blunt, all-or-nothing responses, because a blunt response is the only one a shared global endpoint can make. That means more suspensions, more region locks, and more sudden availability gaps across every major provider, not fewer.
For businesses, the takeaway is simple and it does not depend on which lab you prefer. Pick the best model for the job, and build so that losing it does not cost you your customers. Fable 5 came back in three weeks. The next model might not, and either way, your support desk should never have noticed.
You can read Anthropic’s full account in its redeployment announcement, and see how we approach resilient, model-agnostic AI in our deeper guide to building AI infrastructure that survives losing its best model.

